|
Script Sql d'insertion de Blobs - John COLIBRI. |
- résumé : utilitaire exécutant un Script SQL qui insère des Blobs Interbase dans une Table
- mots clé : Blob - INSERT INTO - Script SQL- Binary Large Object - Interbase
- logiciel utilisé : Windows XP personnel, Delphi 6.0, Interbase 6
- matériel utilisé : Pentium 2.800 Mhz, 512 Meg de mémoire, 250 Giga disque dur
- champ d'application : Delphi 1 à 2006 sur Windows / Interbase
- niveau : développeur Delphi
- plan :
1 - Introduction Très souvent une base de donnée est initialisée par un Script Sql. Si certaines
tables contiennent des Blobs (Binary Large OBjects), la valeur littérale de ce champ non formatté est fournie dans le script. Les outils d'administration de base de données sont capables en général de
construire la base, et remplir les tables en utilisant ce script. Dans le cas d'Interbase, nous pouvons utiliser IbConsole. Il arrive que nous souhaitions effectuer le traitement par une application
fournie à nos clients, plutôt que de les laisser batailler avec IbConsole. Il faut donc arriver à remplir les champs Blobs en utilisant un script. Nous avons présenté auparavant: Nous allons présenter ici comment exécuter les Scripts contenant des valeurs littérales de Blobs
2 - Principe
2.1 - Ecriture de Blob Notre but est de remplir les lignes d'une Table contenant des champs Blob à partir d'un Script Sql. Prenons la table suivante (partie de PROJECT de EMPLOYEE.GDB) définie par:
CREATE TABLE PROJECT
(
PROJ_ID CHAR(5),
PROJ_NAME VARCHAR(20),
PROJ_DESC BLOB SUB_TYPE TEXT SEGMENT SIZE 800
)
| Pour insérer les deux premiers champs, nous pouvons utiliser le script:
INSERT INTO PROJECT
(PROJ_ID, PROJ_NAME)
VALUES ('VBASE', 'Video Database')
|
et pour utiliser cette requête en Delphi, nous plaçons cette requête dans un IbSql, et l'envoyons au moteur:
PROCEDURE insert_into;
BEGIN
WITH IbQuery, Sql DO
BEGIN
Clear;
Add('INSERT INTO PROJECT');
Add(' (PROJ_ID, PROJ_NAME)');
Add(' VALUES (''VBASE'', ''Video Database'')' );
ExecQuery;
END; // WITH IbQuery, Sql
END; // insert_into
|
Pour ajouter une ligne avec une valeur de Blob, le script serait, par exemple:
INSERT INTO PROJECT
(PROJ_ID, PROJ_NAME, PROJ_DESC)
VALUES ('VBASE', 'Video Database', 'Design a video data base management system')
| mais nous ne pouvons pas envoyer la requête telle quelle au moteur. Il faut utiliser une requête paramétrée et un tStream:
procedure insert_into_with_stream;
var l_c_string_stream: tStringStream;
begin
l_c_string_stream:= tStringStream.Create(
'Design a video data base management system');
with IbQuery1, Sql do
begin
Clear;
Add('INSERT INTO PROJECT');
Add(' (PROJ_ID, PROJ_NAME, PROJ_DESCRIPTION)');
Add(' VALUES (''VBASE'', ''Video Database'', :PROJ_DESCRIPTION)' );
ParamByName('PROJ_DESCRIPTION').LoadFromStream(l_c_string_stream, ftMemo);
ExecQuery;
end; // with Query1, Sql
l_c_string_stream.Free;
end; // insert_with_stream
|
Par conséquent - le script pour une table ayant des Blobs est identique à celui d'une table sans Blob
- c'st l'envoi de la requête INSERT INTO qui est différent:
- il faut détecter quels champs sont des champs Blobs
- pour les champs non Blob, il faut remplir la partie VALUES
- pour les champs Blobs, il faut placer la valeur dans un tStream, placer dans VALUES un paramètre SQL, puis appeler LoadFromStream pour charger le paramètres
2.2 - Le Script Sql à analyser Pour fixer les idées, voici une partie du script que nous allons exécuter:
INSERT INTO PROJECT (PROJ_ID, PROJ_NAME, PROJ_DESC, TEAM_LEADER, PRODUCT_ )
VALUES ('VBASE', 'Video Database',
'Design a video data base management system for controlling on-demand video distribution.',
45, 'software');
INSERT INTO PROJECT (PROJ_ID, PROJ_NAME, PROJ_DESC, TEAM_LEADER, PRODUCT_ )
VALUES ('DGPII', 'DigiPizza',
'Develop second generation digital pizza maker with flash-bake heating element and
digital ingredient measuring system.',
24, 'other');
INSERT INTO PROJECT (PROJ_ID, PROJ_NAME, PROJ_DESC, TEAM_LEADER, PRODUCT_ )
VALUES ('GUIDE', 'AutoMap',
'Develop a prototype for the automobile version of the hand-held map browsing device.',
20, 'hardware');
|
3 - Le Projet Delphi
3.1 - Analyse du script Sql Les requêtes sont composées de suites de lignes, se terminant par un terminateur. Par défaut le terminateur est ";". Comme la requête peut contenir
des chaînes littérales (avec éventuellement des ";"), il est plus simple d'utiliser un analyseur lexical (scanner) complet plutôt que de compter les guillemets. Un tel analyseur de script a été présenté dans l'article
exécuteur de script sql et ne sera pas repris ici. Mais cette CLASSe permet de récupérer à chaque appel de f_get_request() une nouvelle requête.
3.2 - Traitement d'une requête Une fois que nous sommes en possession d'une requête, nous devons - récupérer le nom de la Table. Ce nom permet d'utiliser un tIbQuery pour
lancer une requête SELECT, et nous utiliserons les tFieldDefs pour connaître le nom et le type de chaque colonne (tField.Name et tField.DataType
- la liste des noms et types de chaque colonne permet
- de construire la partie fixe de INSERT INTO (tout sauf VALUES )
- d'extraire les valeurs littérales de la requête
- dans une String pour les champs non Blobs
- dans un tStream pour les champs Blobs
et VALUES comportera soit la valeur littérale (champ non Blob) ou
le paramètres SQL (Blob).
3.2.1 - Gestion des valeurs des champs Pour stocker la liste des colonnes, avec le nom, le type, et la valeur (String
ou tStream) d'une requête, nous utilisons une CLASSe auxiliaire définie par: c_field_value=
Class(c_basic_object)
// -- m_name: the field_value name
m_field_type: tFieldType;
// -- filled at parse time
m_field_index: Integer;
m_value: String;
m_c_stream: tStream;
Constructor create_field_value(p_name: String;
p_field_type: tFieldType;
p_value: String; p_c_stream: tStream);
function f_display_field_value: String;
function f_c_self: c_field_value;
Destructor Destroy; Override;
end; // c_field_value
c_field_value_list=
Class(c_basic_object)
m_c_field_value_list: tStringList;
Constructor create_field_value_list(p_name: String);
function f_field_value_count: Integer;
function f_c_field_value(p_field_value_index: Integer): c_field_value;
function f_index_of(p_field_value_name: String): Integer;
function f_c_find_by_field_value(p_field_value_name: String):
c_field_value;
procedure add_field_value(p_field_value_name: String;
p_c_field_value: c_field_value);
function f_c_add_field_value(p_field_value_name: String;
p_field_type: tFieldType; p_value: String;
p_c_stream: tStream): c_field_value;
procedure display_field_value_list;
Destructor Destroy; Override;
end; // c_field_value_list
|
3.2.2 - L'exécution des INSERT INTO
La CLASSe qui exécute le script sql est la suivante: c_insert_ib_blob=
class(c_basic_object)
m_c_ibdatabase_ref: tIbDatabase;
m_c_request: tStringList;
m_c_field_value_list: c_field_value_list;
Constructor create_insert_ib_blob(p_name: String;
p_c_ibdatabase_ref: tIbDatabase);
procedure _create_field_value_list(p_table_name: String);
procedure _insert_into_blob;
procedure execute_script(p_full_script_file_name: String);
Destructor Destroy; Override;
end; // c_insert_ib_blob
|
Depuis le projet principal, nous appelons execute_script en fournissant le nom
du fichier. Le fichier est chargé, et l'analyseur lexical récupère les requêtes individuelles. Il faut alors - construire la liste des champs (les noms et les types)
- récupérer les valeurs littérales, construire la requête et l'exécuter
En général les requêtes INSERT INTO pour une même table se suivent. Il
est donc inutile de recréer une nouvelle liste de nom / types de champs lorsque le nom de la table ne change pas. Voici alors le texte de execute_script, avec cette petite optimisation:
procedure c_insert_ib_blob.execute_script(p_full_script_file_name: String);
var l_request, l_trimmed_request: String;
l_index: Integer;
l_table_name, l_previous_table_name: String;
begin
with c_ib_script.create_ib_script('script', p_full_script_file_name) do
begin
if f_initialized
then begin
initialize_scanner;
m_c_field_value_list:= Nil;
l_previous_table_name:= '';
repeat
l_request:= f_get_request;
if not (m_is_SET_TERM or m_is_COMMIT_WORK or m_is_SET_AUTODDL)
then begin
l_trimmed_request:= f_add_return_line_feed(l_request);
l_trimmed_request:= f_change_returns_in_spaces(l_trimmed_request);
l_trimmed_request:= Trim(f_remove_double_spaces(l_trimmed_request));
if l_trimmed_request<> ''
then begin
// -- get the table name
l_index:= 1;
f_string_extract_identifier(l_trimmed_request, l_index);
f_string_extract_identifier(l_trimmed_request, l_index);
l_table_name:= f_string_extract_identifier(l_trimmed_request,
l_index);
if m_c_field_value_list= Nil
then begin
m_c_field_value_list:=
c_field_value_list.create_field_value_list('field_values');
_create_field_value_list(l_table_name)
end
else
if l_table_name<> l_previous_table_name
then begin
m_c_field_value_list.Free;
m_c_field_value_list:=
c_field_value_list.create_field_value_list('field_values');
_create_field_value_list(l_table_name);
end
else ;
l_previous_table_name:= l_table_name;
m_c_request.Text:= l_trimmed_request;
_insert_into_blob;
end;
end;
until l_request= '';
FreeAndNil(m_c_field_value_list);
end; // could load
Free;
end; // with c_ib_script
end; // execute_script
|
La construction de la liste des noms / types de champs effectué pour chaque nouvelle Table est la suivante:
procedure c_insert_ib_blob._create_field_value_list(p_table_name: String);
var l_c_ibquery: tIbQuery;
l_field_index: Integer;
l_c_field_value: c_field_value;
begin
l_c_ibQuery:= tIbQuery.Create(Nil);
with l_c_ibQuery do
begin
Database:= m_c_ibdatabase_ref;
open_ibquery(l_c_ibQuery, 'SELECT * FROM '+ p_table_name);
for l_field_index:= 0 to FieldCOunt- 1 do
with FieldDefs[l_field_index] do
begin
l_c_field_value:= m_c_field_value_list.f_c_add_field_value(Name,
DataType, '', Nil);
case DataType of
ftBlob : l_c_field_value.m_c_stream:= tMemoryStream.Create;
ftMemo : l_c_field_value.m_c_stream:= tMemoryStream.Create;
// ftGraphic : ;
end; // case
end; // for l_field_index, with FieldDefs
Close;
end; // with l_c_ibquery
end; // _create_field_value_list
|
Et pour chaque requête du script, en utilisant la liste des champs créée pour
chaque nouvelle table: - nous utilisons insert_into:
procedure c_insert_ib_blob._insert_into_blob;
var l_c_ibsql: tIbSql;
l_table_name: String;
// -- here procedure create_ibsql_open_database;
// -- here procedure analyze_request(p_text: String);
// -- here procedure execute_request;
begin // _insert_into_blob
create_ibsql_open_database;
analyze_request(m_c_request.Text);
execute_request;
with l_c_ibsql do
Free;
end; // _insert_into_blob
| - create_ibsql_open_database est trivial
- analyze_request remplit les valeurs littérales des champs:
procedure analyze_request(p_text: String);
var l_index, l_text_length: Integer;
function f_extract_simple_field_value(p_field_type: tFieldType): String;
begin
case p_field_type of
ftInteger, ftSmallint, ftBCD :
Result:= f_string_extract_characters_in(p_text, l_index, k_digits);
ftString : Result:= f_string_extract_pascal_string(p_text, l_index);
else
display_bug_stop('not_implem '+ f_fieldtype_name(p_field_type));
end; // f_string_extract_pascal_string(p_text, l_index)
end; // f_extract_simple_field_value
var l_insert, l_into: String;
l_field_name: String;
l_field_index: Integer;
l_field_index_of: Integer;
l_parenthesis, l_comma_parenthesis: Char;
l_values: String;
l_string_value: String;
begin // analyze_request
l_index:= 1;
l_text_length:= Length(p_text);
l_insert:= f_string_extract_non_blank(p_text, l_index);
l_into:= f_string_extract_non_blank(p_text, l_index);
l_table_name:= f_string_extract_pascal_identifier(p_text, l_index);
skip_blanks(p_text, l_index);
l_parenthesis:= f_string_extract_character(p_text, l_index);
l_field_index:= 0;
repeat
l_field_name:= f_string_extract_pascal_identifier(p_text, l_index);
l_field_index_of:= m_c_field_value_list.f_index_of(l_field_name);
if l_field_index_of>= 0
then
with m_c_field_value_list.f_c_field_value(l_field_index_of) do
begin
// -- also add the CASE SENSITIVE name
m_name:= l_field_name;
m_field_index:= l_field_index;
end;
skip_blanks(p_text, l_index);
l_comma_parenthesis:= f_string_extract_character(p_text, l_index);
Inc(l_field_index);
until l_comma_parenthesis= ')';
l_values:= f_string_extract_pascal_identifier(p_text, l_index);
skip_blanks(p_text, l_index);
l_parenthesis:= f_string_extract_character(p_text, l_index);
l_field_index:= 0;
repeat
with m_c_field_value_list.f_c_field_value(l_field_index) do
if m_field_type in [ftBlob, ftMemo]
then begin
// -- assumes string blob, with pascal '' escape
l_string_value:= f_string_extract_pascal_string(p_text, l_index);
// -- remove start and end quotes
l_string_value:= f_remove_quote(l_string_value, '''');
// -- place in a stream
with tMemoryStream(m_c_stream) do
begin
Position:= 0;
if Length(l_string_value)> 0
then Write(l_string_value[1], Length(l_string_value));
end; // with tMemoryStream(m_c_stream)
// -- "___,___" or "__)__"
end
else begin
l_string_value:= f_extract_simple_field_value(m_field_type);
m_value:= l_string_value;
end;
// -- "___,___" or "__)__"
skip_blanks(p_text, l_index);
l_comma_parenthesis:= f_string_extract_character(p_text, l_index);
Inc(l_field_index);
until l_comma_parenthesis= ')';
end; // analyze_request
| - et voici la construction et l'exécution de la requête
procedure execute_request;
procedure do_exec_sql(p_request: String);
var l_field_index: Integer;
l_parameter_index: Integer;
begin
with l_c_ibsql do
begin
try
if DataBase.DefaultTransaction.InTransaction
then DataBase.DefaultTransaction.Commit;
DataBase.DefaultTransaction.StartTransaction;
Close;
GenerateParamNames:= true;
SQL.Text:= p_request;
Prepare();
l_parameter_index:= 0;
with m_c_field_value_list do
for l_field_index:= 0 to f_field_value_count- 1 do
with f_c_field_value(l_field_index) do
if m_field_type in [ftBlob, ftMemo]
then begin
m_c_stream.Position:= 0;
l_c_ibsql.Params[l_parameter_index].LoadFromStream(m_c_stream);
Inc(l_parameter_index);
end;
ExecQuery;
DataBase.DefaultTransaction.Commit;
except
on e: Exception do
begin
display('*** pb_'+ e.Message);
end;
end; // try except
end; // with l_c_ibsql
end; // do_exec_sql
var l_field_index: Integer;
l_request: String;
l_field_names, l_values: String;
begin // execute_request
l_request:= 'INSERT INTO '+ l_table_name+ ' (';
with m_c_field_value_list do
begin
for l_field_index:= 0 to f_field_value_count- 1 do
with f_c_field_value(l_field_index) do
begin
l_field_names:= l_field_names+ m_name;
if l_field_index< f_field_value_count- 1
then l_field_names:= l_field_names+ ', ';
end; // for l_field
l_request:= l_request+ l_field_names+ ') VALUES (';
l_values:= '';
for l_field_index:= 0 to f_field_value_count- 1 do
with f_c_field_value(l_field_index) do
begin
if m_field_type in [ftBlob, ftMemo]
then begin
l_values:= l_values+ ':'+ m_name;
end
else l_values:= l_values+ m_value;
if l_field_index< f_field_value_count- 1
then l_values:= l_values+ ', ';
end; // for l_field
l_request:= l_request+ l_values+ ')';
end; // with m_c_field_value_list
do_exec_sql(l_request);
end; // execute_request
|
3.3 - Mini manuel  | compilez le projet
| |
| sélectionnez la base dans le DirectoryListBox et FileListBox de l'onglet "dir_" | | |
pour disposer d'une base et de tables d'essais, vous pouvez optionnellement créer la base et les tables (nous avons extrait les définitions de script
généré par extraction des valeurs des Blobs ) Pour cela: - cliquez "create_database_" dans l'onglet "insert_"
- cliquez "create_table_" pour créer les tables "JOB" et "PROJECT" (qui sont les deux seules tables de EMPLOYEE.GDB qui contenaient des Blobs)
- vous pouvez visualiser les tables ou les effacer
Voici la table "PROJET" ainsi créée: 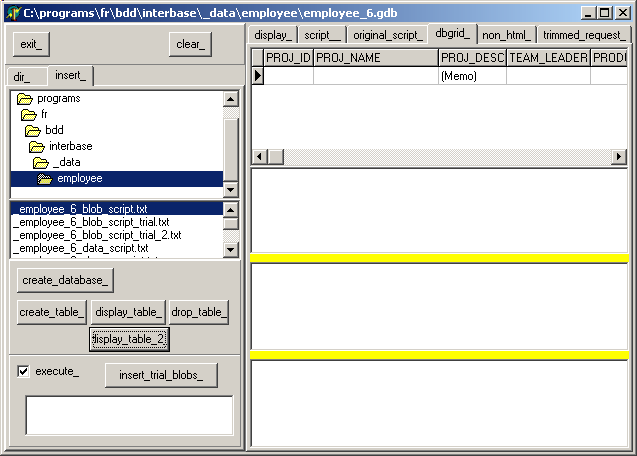 Sinon, si vous souhaitez utiliser une autre base, cette étape n'est pas nécessaire | |
| sélectionnez le script en utilisant la DirectoryListBox et FileListBox de l'onglet "insert_" | |
| remplissez les tables en cliquant "insert_blobs"
|  | cliquez "display_table_" pour visualiser la table et son script
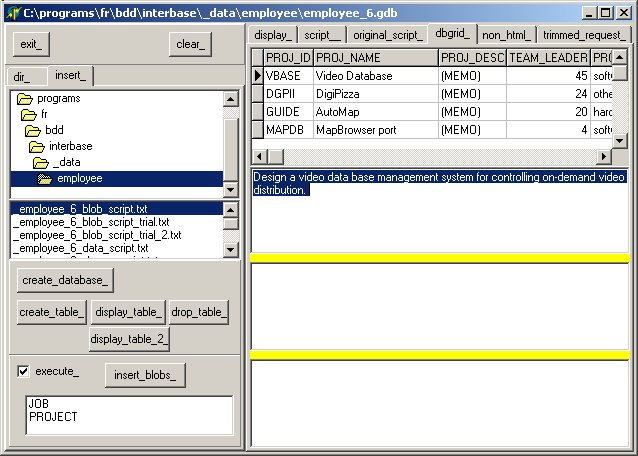
|
4 - Télécharger le code source Delphi Vous pouvez télécharger:
- script_executer_with_blobs.zip : le projet complet qui exécute un script pour charger des Blobs. Nous avons aussi joint les 3 scripts Sql, à
titre d'exemple, pour la table JOB et PROJECT de EMPLOYEE.GDB (68 K)
Ce .ZIP qui comprend: - le .DPR, la forme principale, les formes annexes eventuelles
- les fichiers de paramètres (le schéma et le batch de création)
- dans chaque .ZIP, toutes les librairies nécessaires à chaque projet (chaque .ZIP est autonaume)
Ces .ZIP, pour les projets en Delphi 6, contiennent des chemins RELATIFS. Par conséquent:
- créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Ces .ZIP ne modifient pas votre PC (pas de changement de la Base de Registre, de DLL ou autre). Pour supprimer le projet, effacez le répertoire. La notation utilisée est la notation alsacienne qui consiste à préfixer les
identificateurs par la zone de compilation: K_onstant, T_ype, G_lobal, L_ocal, P_arametre, F_unction, C_lasse. Elle est présentée plus en
détail dans l'article La Notation Alsacienne
Comme d'habitude:
- nous vous remercions de nous signaler toute erreur, inexactitude ou problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections
qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même
les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en
cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site,
ajoutez un lien dans vos listes de liens ou citez-nous dans vos blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
5 - L'auteur John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|