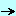|
XSD Viewer - John COLIBRI. |
- résumé : cet outil permet d'afficher la structure d'un document .XML en analysant et affichant dans un tTreeView le fichier .XSD
- mots clé : XSD - XML Schema Definition - analyseur - tTreeView - EDI - XML
EDI - XSD to BNF - BNF - EBNF - IEBNF - Edifac
- logiciel utilisé : Windows XP personnel, Delphi 6.0
- matériel utilisé : Pentium 2.800 Mhz, 512 Meg de mémoire, 250 Giga disque dur
- champ d'application : Delphi 1 à 2006 sur Windows
- niveau : développeur Delphi
- plan :
1 - Introduction La Douane française met en place une procédure de déclaration à domicile utilisant une procédure électronique. Au lieu de transférer des documents
papier, le déclarant échange avec la douane des documents électroniques (cf références ) . La structure des données à envoyer est fourni par un ensemble de fichiers au
format XSD (Xml Schema Definition). Pour analyser ces fichiers .XSD, nous pouvons utiliser des outils du commerce (XML Spy, par exemple), ou analyser directement ces fichiers XSD. Nous avons opté pour l'analyse directe, dont
l'avantage énorme est de pouvoir prolonger l'analyse par d'autre traitements (vérification, génération etc)
2 - Principe 2.1 - Définition de Données
La structure d'un fichier XML peut être définie par deux syntaxes: - un fichier .DTD, qui tend à devenir obsolète car il n'a pas une syntaxe XML
- un fichier .XSD (Xml Schema Definition) qui est un fichier de
structure .XML mais dédié à la définition d'un autre fichier .XML
Le fichier .XSD définit donc - les atomes de base
- l'organisation de ces atomes: la séquence des atomes, les répétitions et les parties optionnelles
Nous retrouvons pour structurer les données la même organisation que pour structurer n'importe quel langage (atomes de base, séquence, itération et test). Pour les langages, l'outil de base pour décrire la structure est la grammaire
BNF (Backus Naur Formalism). Par exemple pour décrire la structure d'une expression telle que: nous pouvons utiliser une grammaire telle que:
expression= term { additive_operator term } .
additive_operator= '+' | '-' .
term= factor { ( '*' | '/' ) factor } .
factor= NUMBER | sub_expression .
sub_expression= '(' expression ')' .
|
| Sans rentrer dans le détail de ce formalisme, vous noterez que: - chaque règle comporte
- des atomes, appelés terminaux (NUMBER, '+', '-', '*, '/', '(' et ')' )
- le nom d'autre règles (appelées non-terminaux). Ainsi dans la définition de term, factor est une règle qui est spécifiée plus bas
- les règles les plus emboîtées correspondent aux règles de précédence des
calculs.Dans le cas de l'expression 11+22*33, 22*33 est calculé avant 11+726. Et par conséquent factor est calculé avant term
Malheureusement les personnes qui définissent XML et ses produits dérivés ne se
sont pas inspirés de BNF, mais on inventé des mécanismes spécifiques pour spécifier les atomes et la structure. Notre exemple simple deviendrait, au niveau du fichier .XML:
<expression>
<term>
<factor>3</factor>
</term>
<additive_operator>+</additive_operator>
<term>
<factor>4</factor>
<mul_operator>*</mul_operator>
<sub_expression>
<parenthesis value="("/>
<expression>
<term>
<factor>5</factor>
<additive_operator>-</additive_operator>
<factor>6</factor>
</term>
</expression>
<parenthesis value=")"/>
</sub_expression>
</term>
</expression>
| | qui peut être spécifié par la grammaire .XSD suivante:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="expression" type="expressionType"/>
<xs:complexType name="expressionType">
<xs:sequence>
<xs:element name="term" type="termType" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="additive_operator" type="additive_operatorType"/>
</xs:sequence>
</xs:complexType>
<xs:element name="term" type="termType"/>
<xs:complexType name="termType">
<xs:sequence>
<xs:element name="factor" type="factorType"/>
<xs:element name="mul_operator" type="mul_operatorType"/>
<xs:element name="sub_expression" type="sub_expressionType"/>
<xs:element name="additive_operator" type="additive_operatorType"/>
</xs:sequence>
</xs:complexType>
<xs:element name="factor" type="factorType"/>
<xs:simpleType name="factorType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
<xs:element name="additive_operator" type="additive_operatorType"/>
<xs:simpleType name="additive_operatorType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
<xs:element name="mul_operator" type="mul_operatorType"/>
<xs:simpleType name="mul_operatorType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
<xs:element name="sub_expression" type="sub_expressionType"/>
<xs:complexType name="sub_expressionType">
<xs:sequence>
<xs:element name="parenthesis" type="parenthesisType" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="expression" type="expressionType"/>
</xs:sequence>
</xs:complexType>
<xs:element name="parenthesis" type="parenthesisType"/>
<xs:complexType name="parenthesisType">
<xs:sequence/>
<xs:attribute name="value" type="xs:string"/>
</xs:complexType>
<xs:element name="additive_operator" type="additive_operatorType"/>
<xs:simpleType name="additive_operatorType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
</xs:schema>
| | Notez que - cette grammaire .XSD de notre expression a été générée automatiquement par
XmlMapper.EXE qui est un outil de traitement de fichiers .XML fourni avec Delphi 6 et suivants
- notre exemple de grammaire .XSD n'est pas parfaite: il est possible de
vérifier qu'un fichier .XML correspond ou non à une grammaire .XSD, mais il n'est pas possible de générer à partir d'un fichier .XML toutes les grammaires représentant la structure de ce fichier .XML. Il manque en
particulier l'alternative (CHOICE) que nous rencontrerons ci-dessous.
- tout le monde pourra en revanche évaluer la concision d'EBNF (5 lignes) par rapport à la verbosité d'.XSD (46 lignes). Ce n'est pas tant le nombre de
lignes qui me gêne que la difficulté à comprendre la structure définie par un .XSD. D'où l'outil qui permet une exploration plus simple du fichier .XSD que nous vous fournissons ici.
2.2 - Grammaire des fichiers .XSD
Nous avons trouvé sur le Web quelques tutoriaux qui décrivent les fichiers .XSD. Nous n'avons pas trouvé de présentation d'une grammaire simple. Les documents de W3C (le consortium de normalisation) sont
disponibles, mais tellement complets et détaillés qu'il sont difficilement exploitables pour une première approche.
Nous avons alors procédé autrement: sachant d'une part que .XSD devait décrire
un structure de donnée, et ayant d'autre part les fichiers .XSD de la Douane, nous avons construit une grammaire, puis un analyseur capable d'analyser ces fichiers là. En fait, pour analyser le .XSD, nous nous sommes appuyés sur les faits suivants:
- les atomes de base sont les types natifs, tels que xs:string
| <xs:restriction base="xs:string"/> | |
- les alternatives sont décrits par des items CHOICE (exemple incomplet)
<xs:choice>
<xs:element ref="CHEQUE"/>
<xs:element ref="CARTE BLEUE"/>
<xs:element ref="LIQUIDE"/>
</xs:choice>
| | - la suite d'items est précisé par une SEQUENCE (exemple incomplet)
<xs:sequence>
<xs:element name="factor"/>
<xs:element name="mul_operator"/>
</xs:sequence>
| | - les items qui ne sont pas des types prédéfinis contiennent un attribut
TYPE qui indique le nom de la balise qui spécifie le type (un peu comme la déclaration d'une variable Pascal):
<xs:element name="factor" type="factorType"/>
...
<xs:simpleType name="factorType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
| | - les items sont de deux types:
- les items simples simpleType
- les items complexes compleType qui contiennent soit des alternatives (CHOICE) ou des séquences (SEQUENCE)
- il existe deux mécanismes d'indirection:
- les items ref :
<xs:element ref="facture"/>
...
<xs:element name="facture" type="type_facture"/>
...
| |
ici l'item ref facture peut être remplacé par l'item ayant le name facture L'utilisation de ref permet de factoriser des items
- les items INCLUDE : plusieurs items peuvent être placés dans un fichier .XSD séparé qui est invoqué au début d'autres fichiers .XSD par un item INCLUDE .
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:include schemaLocation="Composants.xsd"/>
<xs:element name="Declaration">
| | Le principe est le similaire à $i ou USES en Pascal
Nous pouvons alors décrire la structure de fichiers .XSD par la grammaire IEBNF suivante:
xsd_document= SCHEMA { INCLUDE } { item } .
item = element | simple_type | complex_type | annotation .
element= ELEMENT [ item ] .
simple_type= SIMPLETYPE restriction .
restriction = { ENUMERATION | FRACTIONDIGITS | TOTALDIGITS
| LENGTH | MAXLENGTH | MINLENGTH | PATTERN | MININCLUSIVE } .
complex_type= COMPLEXTYPE ( choice | sequence ) .
choice= CHOICE { item } .
sequence= SEQUENCE { item } .
annotation= [ documentation ] .
documentation= DOCUMENTATION .
| |
A partir de cette grammaire, nous avons utilisé notre générateur d'analyseur (un con-compilateur) GENCOT pour analyser les fichiers .XSD.
2.3 - La simplification de la grammaire
Une fois l'analyseur réalisé, il reste encore énormément de texte, essentiellement à cause des mécanismes d'indirection (REF et TYPE
). De plus certaines indirection correspondent à des informations situées dans des fichiers INCLUDE . Nous avons alors simplifié la structure obtenue en utilisant les règles suivantes:
- les items REF sont remplacés par les items qu'ils référencent
- les items TYPE sont remplacés par le détail des types
Cela revient à charger et analyser le fichier .XSD, et tous ses fichiers INCLUDE , et ceci récursivement: - le premier fichier est analysé
- les items INCLUDE permettent de charger et analyser les fichiers correspondants
- la structure complète est alors balayée et:
- chaque item REF est remplacé par sa définition (recherchée en balayant la structure depuis le début)
- chaque item contenant un attribut TYPE est complété par la définition du type
3 - Le Projet Delphi 3.1 - Les classes utilisées Nous avons utilisé les classes suivantes: - l'analyse lexicale est réalisée par c_xml_scanner qui débit le texte en
symboles élémentaire ("<", ">" etc)
- l'analyse est effectuée par c_xml_parser, qui construit une structure en mémoire correspondant au fichier .XSD
- le document .XSD est représenté par une structure arborescente c_xml_text comportant
- c_xml_string: une chaîne de charactères
- c_xml_tag: une balise .XML, avec son nom, sa liste d'attributs, et les
parties nichées entre les balises début et fin
- c_xml_tag_content_list : l'arbre des éléments entre une balise début et fin
- les différentes étapes de l'analyse et des affichages sont regroupés dans
une classe c_xsd_viewer
3.2 - Diagramme de classes UML Nous pouvons représenter les classes par le diagramme UML suivant: Nous avons dessiné en rouge les liens (associations) essentiels.
3.3 - La structure .XML Un fichier .XML est composé de balises et de texte entre les balises:
<?xml version="1.0" encoding="ISO-8859-1"?>
<facture>
<date formatage="123">14 Septembre 2006</date>
<numero>12345</numero>
</facture>
| | Ici:
- facture, date et numéro sont le nom des balises
- la balise date contient un attribut formatage
- entre <facture> et </facture> se trouve une liste de sous-balises (date et numéro)
Le texte le plus général (le nom des balises, le texte entre les balises) est dans la propriété m_name de la classe ancêtre c_xml_string:
c_xml_string= Class(c_basic_object)
// -- m_name: the string
m_c_parent_xml_text: c_xml_text;
Constructor create_xml_string(p_name: String;
p_c_parent_xml_text: c_xml_text);
function f_c_self: c_xml_string;
function f_display_xml_string: String;
end; // c_xml_string
|
Pour des raisons de commodité, chaque c_xml_string contient un lien arrière vers la structure complète (c_xml_text).
Nous représentons les données comprises entre <xxx> et </xxx> par la classe que voici:
c_xml_tag= Class(c_xml_string)
// -- m_name: the tag name
// -- the key="value" lists
m_c_key_list, m_c_value_list: tStringList;
// -- the (optional) content between <xxx> and </xxx>
m_c_xml_tag_content_list: c_xml_tag_content_list;
// -- XSD INCLUDE
m_c_xml_nested_text: c_xml_text;
m_is_ref, m_is_type: Boolean;
m_c_type_tag, m_c_ref_tag: c_xml_tag;
Constructor create_xml_tag(p_name: String;
p_c_parent_xml_text: c_xml_text);
function f_c_self: c_xml_tag;
procedure add_attribute(p_key, p_value: String);
function f_display_xml_tag: String;
function f_display_xml_name_and_attributes: String;
function f_display_attributes: String;
procedure display_strings;
procedure display_xml_tag;
function f_contains_string: Boolean;
function f_key_value(p_key: String): String;
function f_c_get_strings_list: tStringList;
Destructor Destroy; Override;
end; // c_xml_tag
| Notez que:
- chaque c_xml_tag contient un c_xml_tag_content_list, qui est l'arborescence des sous-balises
- pour le cas particulier de notre analyseur de .XSD, nous avons ajouté:
- m_c_xml_nested_text: si la balise est une balise .XSD INCLUDE, c'est là que nous placerons l'arborescence du fichier INCLUDE
- m_is_ref, m_is_type: si l'item est référencé (par un item REF ou par un item TYPE ), le booléen permet de marquer cette balise
- m_c_type_tag: si l'item contient un attribut TYPE, nous placerons dans ce champ le pointeur vers l'item qui définit le type
- m_c_ref_tag: si l'item est un item REF, nous placerons dans ce champ le pointeur vers l'item réel
La structure contenant les sous-balises est représentée par une tStringList
encapsulée. Cette technique a été présentée de nombreuses fois dans les articles sur ce site: c_xml_tag_content_list=
Class(c_basic_object)
m_c_xml_tag_content_list: tStringList;
Constructor create_xml_tag_content_list(p_name: String);
function f_xml_tag_content_count: Integer;
function f_c_xml_tag_content(p_xml_tag_content_index: Integer): c_xml_string;
function f_index_of(p_xml_tag_content_name: String): Integer;
procedure add_xml_string(p_c_xml_string: c_xml_string);
function f_c_find_by_xml_tag_content(p_xml_tag_content_name: String): c_xml_tag;
procedure display_xml_tag_content_list;
function f_contains_string: Boolean;
procedure display_strings;
function f_c_get_strings_list: tStringList;
Destructor Destroy; Override;
end; // c_xml_tag_content_list
|
Finalement le fichier .XML (ou .XSD), composé essentiellement d'un commentaire
et d'une balise (avec ses sous-balises) est représenté par:
t_handle_tag= Procedure(p_c_xml_tag: c_xml_tag) of object;
c_xml_text= Class(c_basic_object)
m_c_xml_comment: c_xml_tag;
m_c_xml_content: c_xml_tag;
Constructor create_xml_text(p_name: String);
procedure display_xml_text;
procedure redisplay_xml_text;
procedure enumerate(p_tag_name: String; p_c_handle_tag: t_handle_tag);
procedure check_xml_strings;
function f_c_search_tag_value(p_tag, p_value: String): c_xml_tag;
function f_c_search_tag_value_nested(p_tag, p_value: String): c_xml_tag;
Destructor Destroy; Override;
end; // c_xml_text
| Mentionnons:
- f_c_search_tag_value_nested qui permettra de rechercher dans l'arborescence emboîtée (avec les INCLUDE ) les items référencés par RER ou TYPE
3.4 - Le scanner La classe est définie par:
c_xml_scanner= class(c_text_file)
m_blank_string: String;
m_symbol_string: String;
m_comment_string: String;
m_symbol_type: t_symbol_type;
constructor create_xml_scanner(p_name,
p_file_name: String);
procedure display_error(p_text: String);
procedure get_symbol;
procedure get_text_symbol;
procedure get_non_comment_symbol;
destructor Destroy; Override;
end; // c_xml_scanner
|
Il s'agit là d'un analyseur des plus classiques.
3.5 - L'analyseur syntactique Le parser est représenté par:
c_xml_parser= class(c_basic_object)
m_c_xml_scanner_ref: c_xml_scanner;
constructor create_xml_parser(p_name: String;
p_c_xml_scanner_ref: c_xml_scanner);
procedure parse_xml(p_c_xml_text: c_xml_text);
destructor Destroy; Override;
end; // c_xml_parser
|
3.6 - La classe c_xsd_viewer Les traitements sont encapsulés dans la classe suivante: c_xsd_viewer=
class(c_basic_object)
m_c_xml_text: c_xml_text;
Constructor create_xsd_viewer(p_name: String);
procedure build_xml_text(p_path, p_recursive_file_name: String);
procedure display_text(p_c_result_list: tStringList);
procedure find_refs;
procedure find_types;
procedure build_treeview(p_c_treeview: tTreeView);
Destructor Destroy; Override;
end; // c_xsd_viewer
|
3.7 - Résultat
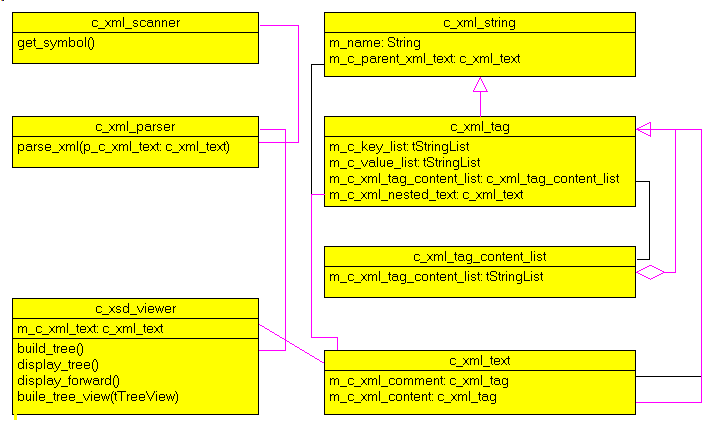
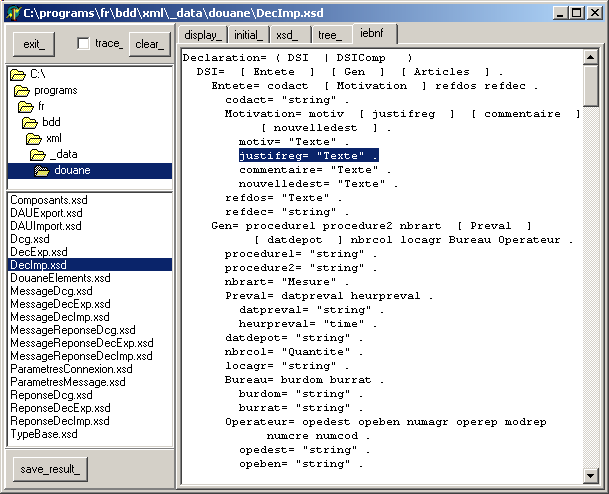
Après avoir placé tous les fichier .XSD de la douane dans le répertoires des données. Voici le début du fichier "DecImp.XSD" (Déclaration d'importation):
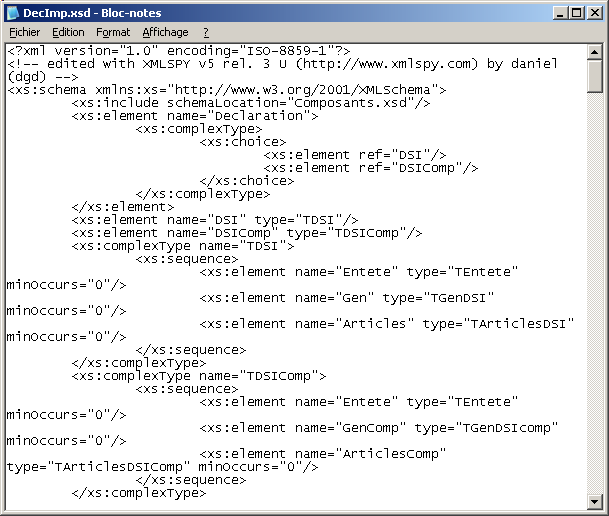
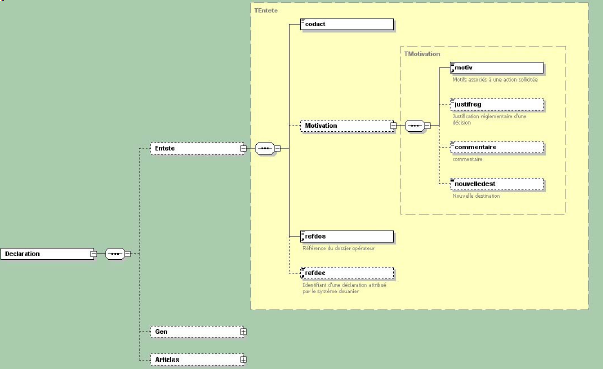
Nous lançons le programme, cliquons le fichier "DecImp.XSD", et le tTreeView est construit et affiché. En sélectionnant la branche "déclaration/ entête / Motivation / justifreg", nous obtenons, par exemple:
A titre de comparaison, voilà l'image fournie par XML Spy présentée dans les documents de la Douane (Delta-D 67-10): Notez que sur ce schéma:
- les alternative et les séquences sont représentés par des petits symboles rectangulaires
- les parties optionnelles sont en pointillé
3.8 - XSD to BNF
Nous pouvons encore aller un pas plus loin en transformant nos .XSD en BNF. L'algorithme est le suivant: - nous démarrons par le premier non-terminal
- les SEQUENCE sont remplacés par des concaténation dans une même règle
- les CHOICE sont remplacés par des alternatives "|"
- la multiplicité 0 (minOccurs="0") provoque une mise entre crochets "[" et "]"
- la multiplicité infinie (maxOccurs="unbouded") provoque une mise entre accolades "{" et "}"
Voici le résultat: Il s'agit là d'un premier jet que nous pourrions affiner.
4 - Améliorations 4.1 - Evaluation de .XSD
Pour un développeur habitué aux techniques de compilation utilisant des spécification BNF, la structure du fichier .XSD est surprenante. Pour rester courtois. TYPE correspond bien à la notion de non-terminal, mais REF est moins évident à traiter.
Nous n'avons d'ailleurs fait qu'égratigner le surface. Voici un schéma découvert dans le document de W3C et qui laisse rêveur:
Si nous ne tenons pas compte de la verbosité, la notation .XML offre tout de même quelques avantages: - les noeuds de la grammaire peuvent contenir plus d'information que la
grammaire BNF simple. Pour un item, nous pouvons ajouter les attributs que nous souhaitons, par exemple des valeurs min, max etc (EBNF ne permet pas de préciser des multiplicité, des tailles de chaîne max etc)
- comme .XML est à la mode, de nombreux outils permettent de traiter ce type de fichier
5 - EDI 5.1 - Le format de départ
EDI (Electronic Data Interchange) est un outil ancien. Il est né des efforts de General Motors pour supprimer les documents papier au niveau de ses commandes avec ses sous-traitants.
L'ancienne version correspond à un fichier de donnée ayant un structure assez compliquée, ayant pour vocation de pouvoir codifier tout type de commande. Vaste programme. Il existe ainsi des normes génériques, et les différents
partenaires sont invités à créer des normes particulières à leur industrie. Un mécanisme d'héritage, en somme. Les développeurs en font des montagnes sur la complexité d'EDI. N'en rajoutons
pas. Si vous avez déjà analysé des fichier .EXE, des .PDF, des .ZIP ou autre format binaire, il n'y a rien de bien nouveau. La principale difficulté est de trouver la documentation précisant la structure à coder.
Il existe d'ailleurs des sources Delphi capables d'analyser les fichiers .EDI, et traiter les fichiers EDIFACT ou UNEDIFACT (voyez Google). Un de nos clients avait ainsi utilisé cette librairie comme point de départ
pour effectuer les déclarations EDI à la MSA (Mutualité Agricole).
5.2 - XML EDI Le format EDI binaire est peu à peu remplacé par un format .XML. Les données
sont échangée dans des fichiers .XML, ce qui est censé simplifier le codage. Dans le cas de la Douane - les fichiers .XSD définissent le format des documents .XML à fournir pour
les déclarations douanières, ainsi que les réponses à ces déclarations
- les fichiers .XML sont envoyés par mail SMTP, en ajoutant un digest SHA1, crypté par l'algorithme RSA avec une signature au format X509. Tout cela
peut bien sûr être effectué en Delphi.
Dans ses notes, la Douane utilise XML Spy, qui effectue en gros le même traitement que notre viewer. L'outil présenté dans cet article avait pour but
uniquement d'explorer la structure des fichiers demandés par la Douane, avec la possibilité d'aller bien plus loin que XML Spy (mapping, validation, génération à partir de base de données etc).
5.3 - WebServices EDI
L'étape suivante consiste à effectuer l'échange EDI en utilisant des services Web, avec les protocoles de sécurisation spécifiques aux services web. La plateforme BizTalk d'IBM serait entièrement fondée sur ce type de traitement.
6 - Télécharger le code source Delphi Vous pouvez télécharger: - xsd_viewer.zip : le projet permettant d'afficher des fichiers .XSD dans
un tTreeView et calculer la grammaire IEBNF (46 K)
- douane.zip : les fichiers .XSD de la douane (26 K)
Ce .ZIP qui comprend: - le .DPR, la forme principale, les formes annexes eventuelles
- les fichiers de paramètres (le schéma et le batch de création)
- dans chaque .ZIP, toutes les librairies nécessaires à chaque projet (chaque .ZIP est autonaume)
Ces .ZIP, pour les projets en Delphi 6, contiennent des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Ces .ZIP ne modifient pas votre PC (pas de changement de la Base de Registre, de DLL ou autre). Pour supprimer le projet, effacez le répertoire.
La notation utilisée est la notation alsacienne qui consiste à préfixer les identificateurs par la zone de compilation: K_onstant, T_ype, G_lobal,
L_ocal, P_arametre, F_unction, C_lasse. Elle est présentée plus en détail dans l'article La
Notation Alsacienne
Comme d'habitude: - nous vous remercions de nous signaler toute erreur, inexactitude ou
problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site, ajoutez un lien dans vos listes de liens ou citez-nous dans vos
blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
7 - Références
8 - L'auteur
John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|